

搜索网站、位置和人员



电话: +86-(0)571-86886861 公共事务部
近日,欧洲计算机视觉国际会议ECCV 2022公布了论文的收录结果,西湖大学工学院李子青实验室、王东林实验室和袁鑫实验室共有4篇成果入选,其中1篇接收为口头报告(Oral presentation)论文。ECCV(European Conference on Computer Vision)是国际顶尖的计算机视觉会议之一,每两年举行一次。本届ECCV 2022论文总投稿数超过8170篇,其中1629篇论文中选,录用率不到20%,而Oral presentation入选率仅为2.7%。
NO. 1
AutoMix: Unveiling the Power of Mixup for Stronger Classifiers
>>>刘梓丞、李思远<<<
李子青实验室2020级博士生
数据混合(Mixup)是深度学习中最有效的数据增广技术之一,它简单易用的特性使其在计算机视觉、自然语言处理等多个领域内被广泛使用。近年来,相关改进工作虽然在不同程度上提升了样本混合策略与标签匹配的精确度,但是也大幅度增加了混合策略的复杂度,在一定程度上违背了数据混合作为数据增广技术应有的轻便性。
针对该问题,我们设计了一种基于数据混合的高效训练框架,可同时实现高分类精度和较低的样本混合复杂度。由于我们设计的Mixup方法是在模型训练过程中由网络自适应的生成混合样本,所以称之为Automatic Mixup(AutoMix)。具体来说,AutoMix训练框架将样本混合策略参数化为一个轻量级模块(Mix Block),该模块被嵌入到主干网络的训练中,可自动生成适用于主干网络任务的增广样本。同时,AutoMix采用了动量更新机制(Momentum Pipeline),可以实现混合样本生成与分类的端到端训练,并且大幅度提升模型的收敛速度。
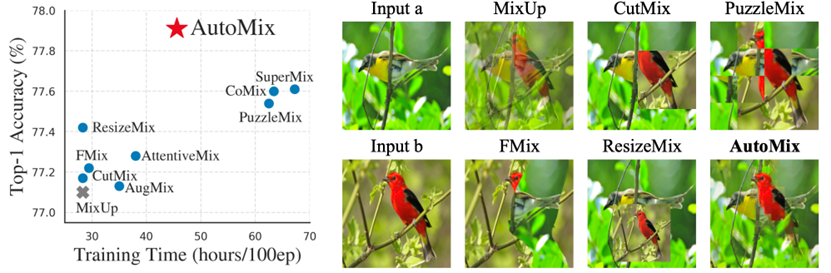
大量的实验和分析表明,AutoMix能稳定提升训练效率,并在各类数据集上超越其它各类混合样本增广算法,达到最先进的性能。下图具体展示了样本混合效果:左图展示了AutoMix在ImageNet数据集上取得了最好的性能,且相对于高复杂度混合算法节约了近一半的训练时间;右图比较的是不同混合策略所生成的增广样本,在给定输入样本a和b的条件下,AutoMix可以精确定位到混合样本中与类别相关的特征区域,为训练提供了高信息量的增广样本。
科普一下
人在识别一个目标或场景的任务中,通常遇到单一目标或场景时会快速做出判断,而遇到多个目标或复杂场景时会先对不确定性进行分析和权衡,再做出较为谨慎的判断。在深度学习中,基于有监督学习训练的分类模型,通常会做出过于自信的(Over-confidence)预测,这主要由数据的单一性和分类标签的唯一性导致。而Mixup技术通过混合样本和对应标签的操作可以让有限的数据变得丰富起来,在模型的训练过程中增加一些较复杂的样本,迫使模型“不得不”考虑更多情况而作出更“谨慎”的判断。我们提出的AutoMix方法便是一种基于Mixup的高效训练框架,在提升模型整体性能的同时还可以大幅度加快模型的收敛速度。
NO. 2
DLME: Deep Local-flatness Manifold Embedding
>>>臧泽林<<<
李子青实验室2020级博士生
数据样本往往是高维的,但与学习任务密切相关的是需要在低维空间里展示高维数据的信息。这种从高维数据中寻求低维嵌入的方法被称作流形学习。在真实情况下,当数据的采样量不足时,流形学习方法的表现不如人意。
本文首先归纳了流形学习的一般过程:即(1)结构构建,在隐空间中建立邻居关系。隐空间是压缩数据的一个表示。隐空间的作用是为了找到模式(pattern)而学习数据特征并且简化数据表示。(2)低维映射,将隐空间中的关系映射到低维嵌入空间(本征维度)。前一步骤中的数据采样不足和后一步骤中不恰当的优化目标导致了“结构失真”和“约束不足”两个问题。
为了解决上面提到的问题,我们提出了一个新的流形学习框架,即深度局部平坦性矩阵嵌入(DLME)。DLME通过数据增强来构建语义流形,并使用基于流形的“局部平坦”假设的平滑度约束来克服“结构失真”问题。另外,我们设计了一个新的损失函数来克服“约束不足”问题,并从理论上证明它导致了一个基于局部平坦度的更合适的嵌入。
为了证明DLME的优势,我们在合成数据集、生物数据集和图像数据集上进行了各种下游任务(含分类、聚类和可视化)。实验结果表明我们提出的DLME胜过最先进的ML和对比学习方法。
科普一下
用图像数据来举例,流形学习可以将每个图像映射到一个隐空间中。在这个隐空间中有三个特点:
(1)语义相似的图像在隐空间中有较近的距离,语义不相似的图像在隐空间中有较远的距离;例如黑狗和白狗的图片的距离近于黑狗和自行车的图片的距离。
(2)隐空间的维度明显小于图像数据的维度;因为图像数据超高的像素数包含了很多冗余维度,不利于对图像的进一步分析。
(3)隐空间的方向有可解释的意义,例如可能存在方向描述物体的颜色,存在方向描述物体的形状等。
更好的流形学习方法可以更精确地构建隐空间,让从原始数据(例如图像)到隐空间中向量的映射函数更能反映原始数据的特点,从而获得更精确的分析效果。
NO. 3
Tree Structure-Aware Few-Shot Image Classification via Hierarchical Aggregation
>>>张敏<<<
王东林实验室2020级博士生
小样本分类(Few-shot classification)的目的是从一组基类(base class)学习可转移的特征表示,并将该表示泛化到带有少量样本的新类(novel class)。由于基类和新类带有不同的类别,导致在基类学习的模型无法提取有助于新类泛化的特征,进而影响模型的表现。因此,如何从有限的可用图像中提取更多的特征,是提高小样本泛化的挑战问题。
借口任务(Pretext tasks)的使用,例如不同角度旋转图像或者随机排布图像RGB颜色等,有助于提取更有用的特征表示。但是我们实验发现,不合适的借口任务有时会损害模型的表现。所以目前大多数工作需要引入专家经验为不同的下游任务选择合适的借口任务,这种方式耗时耗力。
本文我们提出一种自适应的方法—自动选择有助于模型学习的特征表示。具体来说,我们提出了层次树构造组件,它使用边缘信息来建模不同的增强图像和原始图像,并使用层探索在不同借口任务之间的知识。在构建的树结构上,我们还引入了门控选择聚合组件,它使用遗忘门自适应地选择和聚合增强的特征并改进模型的性能。大量的实验结果表明我们的方法可以在四个基准数据集上实现SOTA(State-Of-The-Art)的性能。
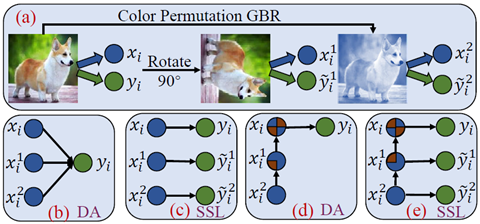
科普一下
如果有一张白色的纸,上面有一个黑色的点,一般人们首先会关注到黑色的点,因为它带有高的信息量。同理,我们希望模型在学习中可以跟人一样有所抉择,并不是把所有知识一股脑的去学习,而是挑选出有助于下游任务的知识去学习,提高下游任务的表现。学会自适应的学习比一股脑的死学全部知识更重要。
NO. 4
Ensemble Learning Priors Driven Deep Unfolding for Scalable Video Snapshot Compressive Imaging
>>>杨承帅、张时语<<<
袁鑫实验室博士后和科研助理
什么是单曝光压缩成像(Snapshot Compressive Imaging, SCI)?
将多个连续但不同的帧画面,通过随机编码的掩模调制后,在不断曝光中叠加为一帧。后期再通过重建算法,恢复出所有的帧画面。
为什么是单曝光压缩成像?
主要是为了提高成像速度:相机的成像速度受CMOS读取和存储的影响,很难提高;而随机编码的速度却较容易提升。
目前单曝光压缩成像发展到什么程度了?
单曝光压缩成像的核心概念是“压缩比”,指的是我们在不断曝光中到底叠加多少帧。叠加8张调制后的图片,压缩比就是8。目前我们可以做到在压缩比为25的情况下确保PSNR达到30以上。
单曝光压缩成像的瓶颈是什么?
是图像的重建算法。当然这和压缩比也有一定的关系。从理论和实验的角度讲,压缩比越高,恢复起来就越困难,恢复的算法就越复杂,恢复效果就越差。这同时也符合人类的直觉。
我们干了什么?
目前主流的单曝光压缩成像的图像恢复大多是基于深度学习的图像重建算法,深度学习由于缺乏可解释性而饱受诟病。前人为此提出了深度展开算法,将传统迭代算法中的去噪项(正则项)更换为经神经网络训练后的降噪项。尽管如此,一个是过分追求重建速度忽略了重建效果,另一个是过分追求重建效果忽略了重建时间。本文采用集成学习,把本来分布在不同级次中的去噪项集成在一起进行学习,增加了去噪项的优势互补,却没有增加神经网络参数。本文可以做到在高速重构的同时又让重建效果达到了目前最优。
其次,基于深度学习的图像恢复算法的可扩展性普遍较差,可扩展性(在SCI中)主要体现在对图像分辨率的不同,压缩帧率的不同以及调制时使用的掩模版不同。本文首次用深度学习实现了同时对图像分辨率、压缩帧率和掩模版的可扩展性。本文可以做到在不同分辨率下让重建效果达到目前最优。
科普一下
图像重建算法可以粗略地分为两大类:第一类是基于凸优化的传统迭代算法,优点是可解释性强,缺点是重建效果差。第二类是基于深度学习的图像重建算法,优点是重建效果好,但可解释性差。
所以,既然各有所长,合并一下不就可以了?虽然思路如此简单,但合并的过程并没有那么简单,研究人员需要对凸优化和机器学习都有深入的了解才行。合并之后,前人的工作走向了两个极端,有的速度快但是效果差;有的效果好但是速度慢。
本文弥合了运行速度和重建效果这对矛盾。重建出的图像既好又快(同时显存占用相对较低,但是这不是主要比较的对象)。同时解决了深度学习对SCI的可扩展性问题。
延伸阅读
以上文章链接:
1. AutoMix: Unveiling the Power of Mixup for Stronger Classifiers
论文链接:https://arxiv.org/abs/2103.13027
论文解说:https://zhuanlan.zhihu.com/p/550300558
2. DLME: Deep Local-flatness Manifold Embedding
论文链接:https://arxiv.org/abs/2207.03160
3. Tree Structure-Aware Few-Shot Image Classification via Hierarchical Aggregation
论文链接:https://arxiv.org/abs/2207.06989
论文解说:https://zhuanlan.zhihu.com/p/543878686
4. Ensemble Learning Priors Driven Deep Unfolding for Scalable Video Snapshot Compressive Imaging
论文链接:https://arxiv.org/abs/2201.10419
最新资讯
大学新闻
学术研究
学术研究
学术研究
学术研究














