

搜索网站、位置和人员



电话: +86-(0)571-85270350 公共事务部
近日,人工智能顶级会议AAAI 2021(第35届)公布了论文的收录结果,西湖大学工学院王东林实验室和张岳实验室共有6位博士生、科研助理的成果入选。AAAI年会(The National Conference on Artificial Intelligence)由美国人工智能协会(Association for the Advancement of Artificial Intelligence)主办,该组织是人工智能领域的主要学术组织之一,创立于1979年。本届AAAI 会议将于2021年2月2日至2月9日期间于线上举办。
NO.1
Deep Transfer Tensor Decomposition with Orthogonal Constraint for
Recommender Systems
陈政聿
王东林实验室2019级博士生
张量分解是多属性推荐系统最有效的技术之一。然而,它在处理三维的用户-项目-属性评分时存在数据稀疏的问题。
为了解决这个问题,我们考虑在张量分解中有效地结合辅助信息和跨域知识。同时,为了解决迁移过程中存在的负迁移问题,提出了一种跨域张量对齐的深度迁移学习方法。
具体来说,我们将深度网络和Tucker分解相结合,提出了一种深度传递张量分解(DTTD)方法,其中提出了一种基于正交约束的堆叠去噪自动编码器(OC-SDAE),以减小学习有效隐式表示时的尺度变化,并引入辅助信息作为对张量稀疏性的补偿。Tucker分解生成域私有的用户和项目的潜在因子,以此来连接OC-SDAEs的中间层潜在因子,并创建一个跨域共享的核心张量来连接不同的域。
同时,源域和目标域中两个核心张量之间的对齐问题是基于张量分解的迁移学习的一大挑战。为解决这一问题,我们提出了一种跨域对齐算法(CDAA)来解决源域和目标域中两个核心张量之间的misalignment问题。
在多个跨域多属性推荐系统的实验表明,我们所提出的DTTD的性能优于现有的工作。
【科普一下】
拿网络购物来举例,深度传递张量分解(DTTD)可以帮助“猜你喜欢”之类的商品推荐系统缓解稀疏性的问题,主要通过结合相关辅助信息(比如用户性别、年龄、在页面停留的时间,当前的互联网热点),及加入跨域知识(比如用户如果在图书类app购买了多本图书,通过这些图书学到的彼此关联的知识,可以在电影票app平台应用这个相似的关联知识,从而发现影片之间的关联,推荐对应的影片);研究者发现,结合辅助信息和跨域知识后的推荐效率可提升10%以上。
关于跨域迁移中存在的挑战,依然用网购场景举例:比如一个是酒店app,一个是图书app,他们的商品和用户群可能完全没有重叠。在这个情形下该如何利用看似毫无关联的信息?针对这一挑战,研究者因而提出了跨域对齐算法(CDAA)的办法,在发挥这些信息作用的同时,能够摒弃掉无效信息。
NO.2
Attributes-Guided and Pure-Visual Attention Alignment for Few-Shot Recognition
黄思腾
王东林实验室2019级博士生
小样本识别的目标是在每类只有少量有标签样本可供使用的限制下识别新的类别。受到人类学习过程的启发,现有的一些方法引入了额外语义模态来增强从训练样本(称为支持样本)学习更好的表征。然而,这些方法忽视了为测试样本(称为查询样本)设计特殊的处理机制。在失去了潜在的效果提升的同时,这些方法可能导致模态混合表征和同类别的纯视觉表征之间存在偏移,最终导致识别的错误率上升。在本文中,我们提出一种属性指导的注意力模块(AGAM),来使用人工属性标注学习更有区分性的特征。这种即插即用的模块能够利用视觉内容和对应的属性标注一起关注支持样本中重要的通道和区域。同时,对于属性标注不可得的查询样本,这种特征选择过程同样能够只利用视觉内容便可执行。因此,两种样本的表征经过了相似的细粒度优化。另外,我们提出一种注意力对齐机制,来从属性的指导蒸馏知识到纯视觉的特征选择过程,使其能够在不利用属性标注的限制下学会关注更具语义的特征。大量的实验和分析表明,我们提出的模块可以显著改进现有的基于度量的方法来达到最先进的性能。
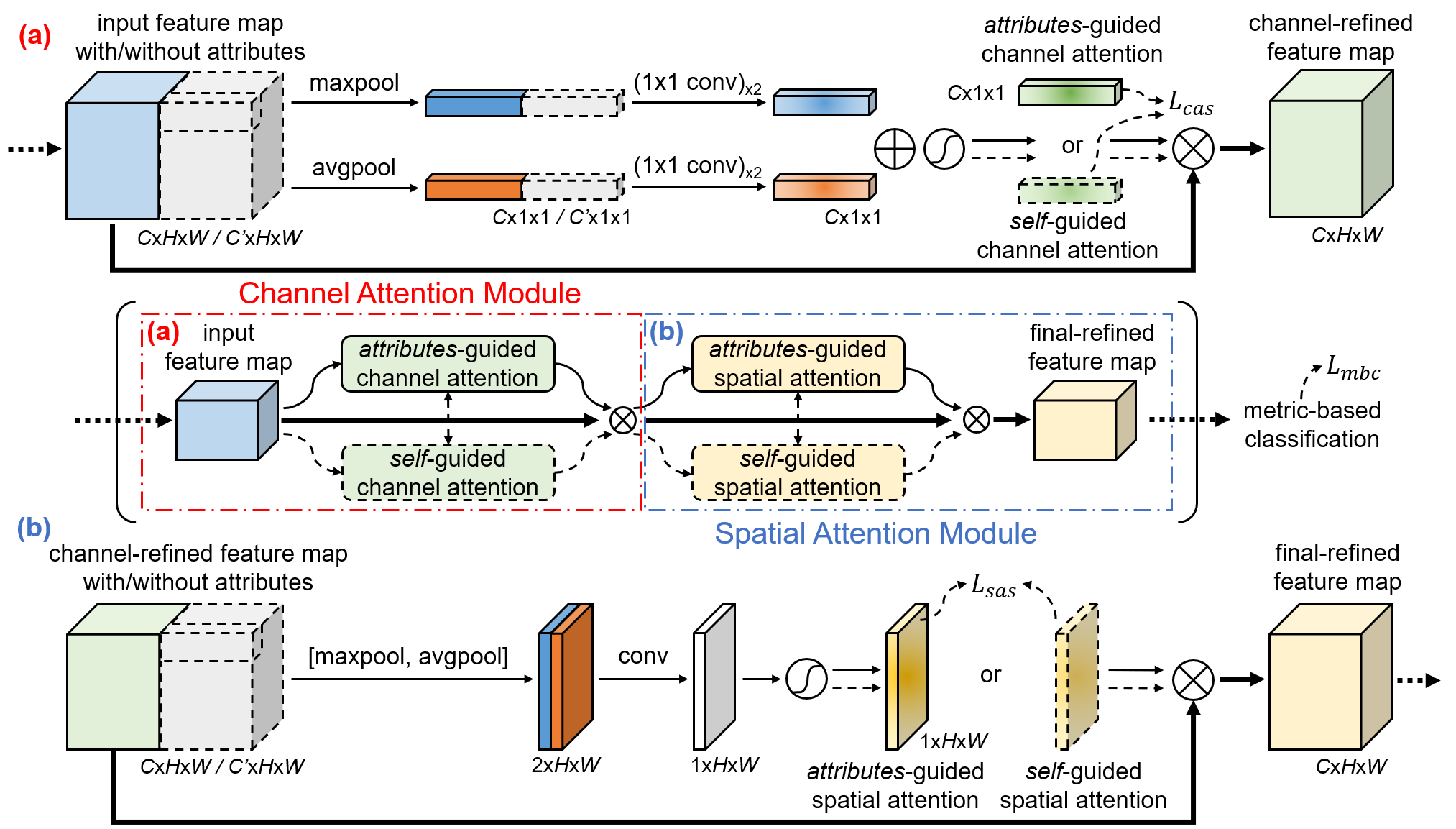
AGAM的总体架构。取决于图像的属性标注是否可得,属性指导分支和自我指导分支中的一支被选择。输入的特征依次经过 (a) 通道注意力模块和 (b) 空间注意力模块来获得最终改善的特征。
【科普一下】
回想一下,你的父母是如何教你认出熊猫的?他们是不是说了“黑眼眶”、“黑白相间的毛”、“吃绿色的竹子”?这些重要信息,成为了无论熊猫在爬树、行走还是坐着,你都能认出这种动物的线索。像这样的语言描述,即为一类语义信息,在样本数据较少的情境下(即小样本情况),能够极大地帮助模型“认出”图像内容,大大提高识别正确率——这正是本研究设计的属性指导的注意力模块(AGAM)的作用(应用在三种经典网络上,提升最高可达22.8%)。
简要来讲,机器人将能像人类的小朋友一样去学习,除了张大眼睛“看”,还能通过关键性的语义信息指导,去更好地认识“世界”。
NO.3
A General Offline Reinforcement Learning Framework for Interactive Recommendation
肖腾
王东林实验室科研助理
本文主要研究如何在不需要在线探索的情况下,从日志的反馈中直接离线学习用户的偏好。本文通过提出通用的离线强化学习框架来最大化累积的用户奖励。具体来说,我们首先将最大化奖励的决策问题建模成一类通用的概率生成模型,然后提出有效的推理算法。为了更有效地进行离线学习,我们提出了五种方法来最大程度地减少分布日志记录策略和推荐策略之间的不匹配,分别为支持集约束、监督正则、策略约束、双重约束和奖励增强。我们在两个公共的现实世界数据集上进行了广泛的实验,证明了所提出的方法可以取得优于现有算法的性能。
【科普一下】
一方面,在需要和用户交互的情形下,既有的强化学习算法往往需要反复与用户进行交互,才能给出最大化满足用户期待的决策(如药物推荐),用户(即“真实环境”)在这种情景下是必须的;同时,这也意味着必须在线、不能离线进行训练;另一方面,既有的监督学习算法给出的决策,无法满足接下来用户未来很长一段时间的需求。而倘若应用了本文提出的通用离线强化学习框架,能够基于大量相似已有的日志数据进行离线学习。从而,能够将未来很长一段时间纳入考虑,向用户提供最佳的决策。
NO.4
Brain Decoding Using fNIRS
曹路
张岳实验室2017级博士生
深度学习的基础是受神经元活动基本原理启发而设计。之前的研究表明人类在进行语言活动的同时产生的神经元信号也可能蕴含了语言类信息,我们认为这些信息可能可以被进一步用于探索NLP模型的设计等NLP问题。我们的工作是AI、心理学、认知科学以及神经科学交叉学科研究,也是未来一系列工作的先导研究,目的是为了确定神经元信号中确实蕴含了可以被区分的语义信息。我们使用功能性近红外光(fNIRS)收集了人类在进行概念解析任务时的神经元活动数据,并且借助词向量实现了对神经元数据的解码。这一研究表明,fNIRS信号中蕴含了可以被分辨的语义信息,并且该语义信息和现有分布式概念表征存在一定程度的关联。这一工作为下一步进行复杂语言任务提供了技术指导。
【科普一下】
AI研究的理想状态是机器能像人类一样思考,如果你认同这种说法,那么,人类就是机器模型比照的标准。
为什么人能轻松辨别出“电影很好”和“电影很好,不是吗?”两句话的区别,而机器却感到困惑?出于这个动机,研究者决定看看人类是如何作出正确判断的——他们收集了十几位实验对象在看到48个文字、图片时候的生理数据,比如神经元活动、脑电波等,看看人类在辨别这些符号时(比如看到了一架飞机),身体有怎样的反应。下一步,他们将根据这些反应,倒推出实验对象看到的是哪些图片和文字(倒推出看到的是飞机),如果能成功,证明这些信息是可以进一步利用的。最终研究人员期望能用这些信息,“教”出更“聪明”的AI。
NO.5
Contextualized Rewriting for Text Summarization
鲍光胜
张岳实验室科研助理
作为自动摘要生成的一种常用方法,抽取式摘要生成技术通常能够将原文中比较重要的内容选出,同时比较好地遵照原文的意思。但是,这种方法生成的摘要也会包含一些不相关或者重复的内容,而且句子之间缺少衔接导致上下文的一致性和可读性比较差。
为了改善这些问题,改写式摘要生成技术通过对抽取式摘要内容进行改写,使其更加简练和通顺。本文在当前改写式摘要生成技术的基础之上,结合被改写内容的上下文,提出了基于上下文的文本摘要改写方法。该方法在改写抽取内容时,考虑其上下文,将重要的缺失信息(如人名、地名等)从上下文中找出,合并到生成的摘要内容中。同时,根据生成的摘要内容前后语句上下文,将冗余的信息剔除,结合代词和连词使摘要内容更通顺易懂。
实验表明,本文的方法显著超越当前最好的改写式摘要生成模型。同时,本文的方法对不同抽取式摘要系统生成的摘要内容都能显著改善。更进一步的,本文将提出的方法抽象成一个通用的模型框架----基于分组对齐的序列到序列生成模型(Seq2seq with Group Alignments),使其可以应用到其它文本生成问题上。
【科普一下】
如何让机器生成文本摘要,这方面的研究已有几十年的历史。抽取文章中的关键语句,并在此基础上进行改写,从而生成摘要,是目前主流的机器生成摘要的三大类方式之一。
本课题改进了该方法,简单来讲,就是让机器进一步通过看全文,对该方法产出的摘要进行进一步的“润色”——主要是补充关键信息、简练冗余内容、增强连贯性。经过自动化指标评测(摘要的评测指标)和人工的评测(准确性、可读性、重要信息的召回和简洁性4大方面),改进后的摘要包含的重要信息更多、文字更精练且可读性更佳。
NO.6
Natural Language Inference in Context - Investigating Contextual Reasoning
over Long Texts
刘汉蒙
张岳实验室2018级博士生
自然语言推理(NLI)是自然语言处理的一项基本任务,主要研究两个文本之间的蕴含关系。流行的NLI数据集是对该任务句子级别的研究。它们可以用来探讨语义表示,但并未涉及基于长文本的上下文推理,而这是人类推理过程的自然组成部分。我们提出了ConTRoL数据集来用于研究长文本的上下文推理。ConTRoL由8,325个专家设计的带有高质量标签的“上下文-假设”对组成,是一个段落级别的NLI数据集,重点关注复杂的上下文推理类型,例如逻辑推理。它是从竞争性甄选和招聘测试(推理测试)衍生而来的,具有很高的质量。与以前的NLI基准相比,ConTRoL中的材料更具挑战性,涉及多种推理类型。
实证结果表明,最先进的语言模型在ConTRoL上的性能表现远不如受过良好教育的人类。我们的数据集还可以用作下游任务(如检查摘要的事实正确性)的测试集。
【科普一下】
简单来说,这是个给机器出的“题库”(即数据集),主要测试机器基于上下文的逻辑推理能力,关注的是机器学习中的盲区或痛点。这个“题库”发布后,大家可以用它测试自己的模型。现有的自然语言处理领域中的已有模型,包括本文所涉及的自然语言推理领域,机器已能取得较高的分数。而在这个新“题库”中,本文发现,机器的表现相当不理想。因而,该研究证实了现有机器学习中的逻辑推理盲区,亦欢迎更多的研究人员加入进来,拿不同的模型来进行测试。
最新资讯
学术研究
学术研究
学术研究
大学新闻














