

搜索网站、位置和人员



电话:

一个人工智能方向的实验室,招了一名文科生读博士,会不会有点奇怪?
本期由西湖大学研究生会主办的Lab Show走进的就是这个实验室。它的研究方向很热门——自然语言处理(NLP)。这是融合语言学、计算机科学、数学于一体的科学,通俗点说,就是教机器学会人类的语言,要能翻译,能对话,能读文章,甚至能写总结和心得体会……
所以,招收文科生,一点也不奇怪。因为这是一项跨越人类语言与机器算法、跨越人脑与电脑、跨越感性与理性的艰巨任务。而接受这项挑战的,正是工学院PI张岳老师带领的文本智能实验室。

张岳
2003年毕业于清华大学计算机科学专业,获得学士学位;
2006年毕业于牛津大学计算机科学专业,获得硕士学位;
2009年毕业于牛津大学计算机科学专业,获得博士学位;
2010年3月~2012年6月在剑桥大学计算机科学专业从事博士后研究;
2012年7月~2018年8月在新加坡科技与设计大学担任助理教授;
2018年9月全职加入西湖大学,担任终身副教授。
死记硬背,还是触类旁通
和人类学英语一样,机器学语言,也需要掌握听、说、读、写、译等各项技能。怎么学?先从语言本身入手,我们来看看翻译这件事。

自然语言处理的应用-机器翻译
自然语言处理起源于上世纪50年代。那时美国与苏联冷战,为了第一时间了解对方的最新动态,取代人力的机器翻译应运而生。最初的做法,是邀请一群语言学家去分析句法结构,然后由计算机科学家写成机器能看懂的规则去翻译。这种生硬地对应翻译,体验感自然很糟糕,文不对题的情况常常出现。
到了上世纪80年代,统计学的方法开始占上风,就是从人类翻译的海量文本里统计出语言学特征,然后再用概率模型告诉机器,翻译的准确率大大提高。
张岳入行那年,也就是2006年,仍是统计学方法方兴未艾的时候。但很快,到了2011年,自然语言处理领域又迎来一次革新,科学家们发现,让机器利用深度神经网络进行学习效果更好。我们可以把它想象成一场更大规模的题海战术,一端输入海量的题干,一端输出海量的标准答案,通过源源不断的“端到端”的数据训练,让机器学习听人话、说人话。
填鸭式的训练后,便是我们今天熟悉的人工智能。他们不仅在翻译上进步了,还学会了与人聊天,更学会了唱歌、写诗这些看上去“逆天”的功能。
但在张岳眼里,这些都还只是停留在“死记硬背”的阶段。
“人不一样,人会举一反三,学了写诗,可能写散文的能力也提高了;学了音乐,对绘画创作又提供了灵感。但机器还不行,而且机器有数据依赖,一旦输入给它的数据不对,输出就会出问题,它还不具备甄别能力,而这也是因为机器的学习不是去理解,而是去‘背’。”
所以,专注于自然语言处理的张岳,想在让机器学会“触类旁通”这件事上取得突破。
事实上,世界上很多研究自然语言处理的实验室都在朝这个方向努力,有的专攻情感分析,有的钻研词法句法,有的侧重人机对话……专业术语如“文本预处理、词法分析、句法分析、语义理解、分词、文本分类、文本相似度处理、关系识别、事件抽取、情感倾向分析、文本生成”等,不同的训练任务背后,都有无数科学家在专项研究。
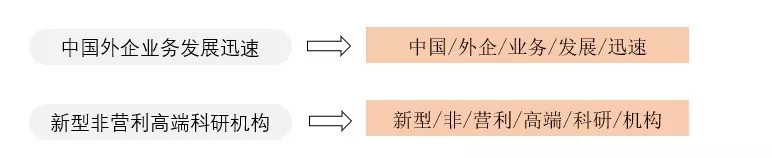
基础自然语言处理研究-分词
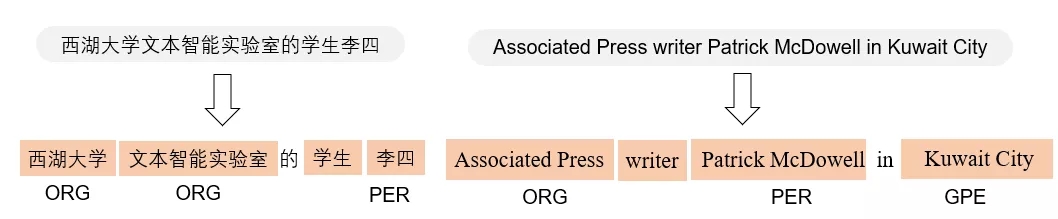
基础自然语言处理研究-命名实体识别
在这个领域,张岳实验室的独特之处在于,他围绕语言理解和生成,对多项任务同时开展研究。
“我团队有20多个人,都是做基础研究的,上面举例说到的大多数任务都有涉及。我们正在努力实现的,是一个跨领域、跨任务、跨语言、跨标注规范的联合训练模型,让机器也能融会贯通。因为自然语言处理每个环节上的任务都要涉及过,才能找到或者设计出触类旁通的‘机关’。”
现在,他们已经在自然语言处理的一系列任务上,取得了文献中领先的速度与准确度。以句法分析为例,2013年,张岳的算法ZPar在标准测试集上取得了比竞争对手Berkeley和Stanford parser更高的准确度和15倍以上的速度优势,直到现在他们还在继续不断推进句法分析最前沿性能的发展;另外,在信息抽取中的实体、关系、事件、情感等很多数据集上,他的实验室也保持了在文献中领先的结果。
张岳希望,下一代自然语言处理,是具备引申、总结、推断能力的,“比如能把从新闻上学到的知识,运用到小说领域。”
电脑,还是人脑

前景令人心潮澎湃,但实践仍需脚踏实地。虽然“深蓝”在22年前打败了人类国际象棋大师,AlphaGo在3年前战胜人类围棋世界冠军。但具体到学语言这件事,电脑花了六七十年,还只是会一点皮毛。
因为学语言,不仅要琢磨语言和文化,还要去研究控制语言的大脑,通过研究人的神经系统去优化机器的神经网络。
张岳引用了一则经典谬误:
英语中有一句成语,the spirit is willing but the flesh is weak,意思是“心有余而力不足”。可到了当时某机器翻译系统那里,被翻译成俄语、再翻译回英语时,变成了the vodka is strong but the meat is rotten,意思是“伏特加很烈,而肉已经烂了”。
差之毫厘,谬以千里。这是因为,语言不仅会产生“歧义”,而且还是一门动态的艺术,它所承载的是庞杂的、不断发展的文化。
比如不同时代有不同的新词黑话,95后常用的XSWL,能有几个70后知道是“笑死我了”的意思,于是语言“代沟”出现了。比如同样的词在不同语境、不同文化下会被赋予不同的含义和情感色彩,美剧《生活大爆炸》主角Sheldon常常听不出话里有话的“讽刺”,不知道在这项任务上机器又能得几分?

美剧《生活大爆炸》剧照(动图来自网络)
“解决这些难题,有几条路可以走。一种是知识图谱和神经网络的结合,把人类的常识、知识、经验建成一个知识库,然后灌给机器,增强它的推理能力;另一种就是研究新的神经网络结构。”张岳说。
后面这一种需要结合脑科学、认知科学等跨学科的知识,这种学科交叉正在国际上成为一种趋势。斯坦福大学在2018年底成立的Human-Centered AI Institute(以人为本人工智能研究院),正是着重人工智能与脑科学和认知学的交叉研究。
在西湖大学,这样的学科交叉得到了最有力的鼓励和支持。从工学院到生命科学学院,步行耗时不超过五分钟,张岳就搜寻到了他的合作伙伴。
一个是生命科学学院的孙一,他的实验室以社会认知的神经网络计算原理为研究对象。另一个是同属工学院的讲席教授、加拿大两院院士Mohamad Sawan,他研究的是与大脑相关的各种疾病的诊断、预测和治疗,并涉足脑机界面等新兴领域。
“孙一以果蝇为研究模型,通过成像技术能看到果蝇脑部的神经结构和神经行为。但果蝇不会说话,所以我还需要和Sawan教授合作,他研究人脑、脑机接口,可以去看和语言相关的神经信号。”张岳说。
虽然科学家对人脑的理解还十分有限,大脑依旧是人体最神秘的器官,张岳坚信这是一个值得尝试的方向。
得到,还是失去
说到这里,也许有人会生出另一种担忧,当机器真的如人一般说话和思考,那是一幅怎样的图景?回到最初的原点,我们为什么执着于让机器学会人的语言?
“为了提高效率。”张岳脱口而出。
从工业革命开始,几乎每一次技术革命都把人类从一些简单重复性的劳动中解放出来。及至互联网时代,人类生产并记录了浩如烟海的“大数据”,基于这些大数据开发,我们的工作和生活方式正在发生一些颠覆性变革,比如机器可以阅读大量法律条文、文献资料、数据报表,替人类完成最索然无味的基础工作,并提供决策建议和依据。下班回家,机器可以帮你开灯、开空调、煮饭泡茶……
“这些数据的阅读和分析,靠人哪里读得完,所以我们试图用一种更聪明地方式读懂互联网,能够把信息有效地提供给决策者。”
再精准一点,张岳实验室试图让自然语言处理的技术服务资本市场。资本市场是为实体经济调配资源的一种机制,“去杠杆”、“供给侧改革”,都是希望更科学地调配资源,而这方面的决策需要整合多方面、多层次的信息,大到企业年报、财经评论,小到社交媒体每一条评论、每一次点赞。
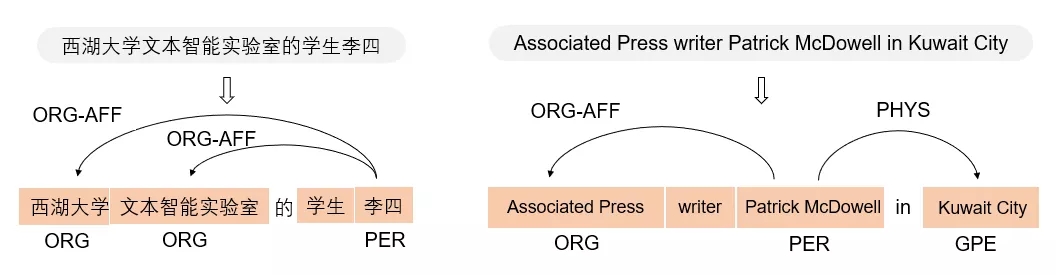
自然语言处理的应用-关系抽取

自然语言处理的应用-情感分析
当然,帮助法律裁决的人工智能,是否带有偏见;提高生活质量的个人助理机器人,是否会让人失去基本的生活能力;智能社交的发展,是否会扭曲人的心智;甚至机器之间会不会学会一种人类不懂的语言……这的确是令人纠结的问题。人工智能技术潜在的威胁,以及英剧《黑镜》借黑科技描述出来的人性黑暗面,张岳不是没有预见到,但他更愿意保持乐观。
“其实,即使人工智能在现阶段,也可能给人类带来危害,问题在于我们怎么规范它。”张岳说,事实上,每一次技术革命后,人都活得比以前更累了,我们需要不断适应新技术,需要从事更富创造力的工作,也会有新的、更具挑战性的工作被创造出来。“换句话说,更烧脑了。”
和人类历史上每一次重大的技术革命一样,人工智能的飞速发展令人兴奋,也催人反思。有得必有失,得失之间如何平衡、如何把握,便倚赖我们人类自己的思考和处世哲学了。
最新资讯
学院新闻
遇见WeMeet














